Transaction: Isolation Level
트랜잭션(Transaction)의 성질인 ACID 중에서 격리 수준(Isolation Level)에 대해서 자세히 정리해보자. 회사에 신입을 막 입사해서 스프링 프레임워크에서 @Transactional 어노테이션을 만났을 때, 얇게 알아봤다. 따로 정리하지 않아서인지 그동안 트랜잭션 환경없이 개발을 막해서인지는 몰라도 기억에 남는게 하나도 없다. 이번 도전에서도 부끄러웠다.
격리 수준은 크게 4가지로 나눈다. 각 격리 수준의 특징을 살펴보고 발생할 수 있는 문제에 대해서 정리해서 어떤 상황에서 어떤 격리 수준을 사용할지 판단할 수 있는 능력을 키워보자.
Isolation Level
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
참고로 오라클(Oracle)은 기본 값으로 READ COMMITTED, MySQL은 기본 값으로 REPEATBLE READ로 사용하고 있다. 스프링 프레임워크에서는 명확히 지정해주지 않고 @Transactional 를 사용하면 데이터베이스의 기본 값에 따라 동작한다.
READ UNCOMMITTED
READ UNCOMMITTED 격리 수준은 한 트랜잭션 안에서의 변경 사항이 다른 트랜잭션 안에서 읽을 수 있다. 트랜잭션의 커밋이나 롤백이 있지 않는 상황에서 다른 트랜잭션 안에서 해당 변경 사항에 접근할 수 있어 데이터를 처리할 수 있다. 그러나 앞서 트랜잭션이 롤백이 되었을 때, 이미 다른 트랜잭션에서는 이 롤백한 상황을 알 수 없고 계속해서 데이터를 처리한다.
트랜잭션의 커밋이나 롤백이 이뤄지지 않은 상황에서 다른 트랜잭션이 변경 사항을 읽을 수 있는 상황을 **더티 리드(Dirty Read)**라 한다. 간단하게 서술한 내용을 실제 로컬 환경에서 재현해보자.
- 트랜잭션 격리 수준 변경
- 테스트 환경 구축
- 트랜잭션(
Transaction A)에서 데이터 변경 - 트랜잭션(
Transaction B)에서 데이터 조회 - 트랜잭션(
Transaction A) 롤백
1. 트랜잭션 격리 수준 변경
MySQL에서 격리 수준의 기본 값은 ‘REPEATABLE READ’ 다. 해당 격리 수준에서는 더티 리드를 확인할 수 없기 때문에 격리 수준을 ‘READ UNCOMMITTED’으로 변경하자.


2. 테스트 환경 구축
테스트 환경을 구축하기 위해 local 데이터베이스를 만들고 product 테이블을 생성한다. 그리고 테스트 데이터를 넣어준다. 아래는 처음에 만든 테스트 데이터다.

3. 트랜잭션(Transaction A)에서 데이터 변경
트랜잭션을 하나 시작해서 데이터를 수정해보자. 테스트 데이터 중, id 값이 2인 아이패드의 개수를 20에서 16으로 변경한 내용이다. 이 데이터 변경은 트랜잭션이 아직 끝나지 않은 상태이다.
Transaction A:

4. 트랜잭션(Transaction B)에서 데이터 조회
다른 트랜잭션을 하나 더 시작해서 해당 데이터를 조회해보자. 서로 다른 트랜잭션이지만, Transaction A에서 변경한 내용이 아직 커밋이나 롤백이 되지 않았음에도 불구하고 Transaction B에서 해당 변경 내용을 조회할 수 있다. 이 상황을 더티 리드라고 한다.
Transaction B:

5. 트랜잭션(Transaction A)을 롤백
앞서 Transaction A에서 변경한 내용을 롤백해보자. 두 트랜잭션 모두다 이전과 같이 같은 결과를 얻는다.
READ COMMITTED
READ COMMITTED 격리 수준은 한 트랜잭션 안에서 아직 커밋이 되지 않은 변경 사항을 다른 트랜잭션 안에서 읽을 수 없다. 다시 말하면 더티 리드 문제가 발생하지 않는다. 그러나 더티 리드 문제가 해결되었다해도 여전히 문제가 있다. 바로 NON-REPEATABLE READ 문제다.
더티 리드 문제를 재현한 과정을 다시 한번 실행해보자. 그리고 마지막에 Transaction A를 커밋하고 Transaction B에서 데이터를 다시 조회해보자.
Transaction B:

Transaction A가 커밋되지 않았던 시점에서는 더티 리드가 발생하지 않아 아이패드의 수량이 여전히 20이다. 그러나 Transaction A가 커밋된 이후 데이터를 조회해보면 아이패드의 수량이 16으로 변경되어 있다. 간단히 말해서 한 트랜잭션 안에서 조회 결과가 달라진 것이다. 이 상황을 NON-REPEATABLE READ라 한다.
한 트랜잭션 안에서 조회 결과가 달라지면 무슨 문제가 발생할까. 상품을 구입하는 과정을 생각해보자. 9,000원인 상품을 주문하는 과정에서 판매자가 가격을 10,000원을 올렸다면 주문 과정에서 9,000원이었던 주문 내역서와 달리 다시 조회한 결과인 10,000원을 결제 해야할까. 이렇게 트랜잭션 안에서 조회 결과가 달라진다면 데이터를 처리하는데 문제가 발생한다.
REPEATABLE READ
REPEATABLE READ 격리 수준은 NON-REPEATABLE READ 문제를 해결했다. 한 트랜잭션 안에서 데이터를 계속 조회해도 그 결과가 달라지지 않는다. 그러면 어떻게 해서 이 문제를 해결했을까.
NON-REPEATABLE READ 문제 해결을 위해 MySQL의 InnoDB 엔진에서는 Undo 로그를 도입했다. Undo 로그는 데이터가 변경이 있을 때, 이전 데이터에 대해 기록한 로그이다. 한 마디로 스냅샷이다. 트랜잭션은 각각 고유의 트랜잭션 ID가 존재하고 이 ID 값을 계속해서 증가한다. 따라서 Undo 로그에 데이터와 트랜잭션 ID를 같이 기록하고, 데이터를 조회하는 트랜잭션의 ID를 기준으로 Undo 로그 살핀다. 격리 수준을 REPREABLE READ로 변경하고 앞서 진행했던 과정을 반복해보자. 한 트랜잭션에서 같이 결과가 계속 나오는 것을 확인할 수 있다.
Transaction B:
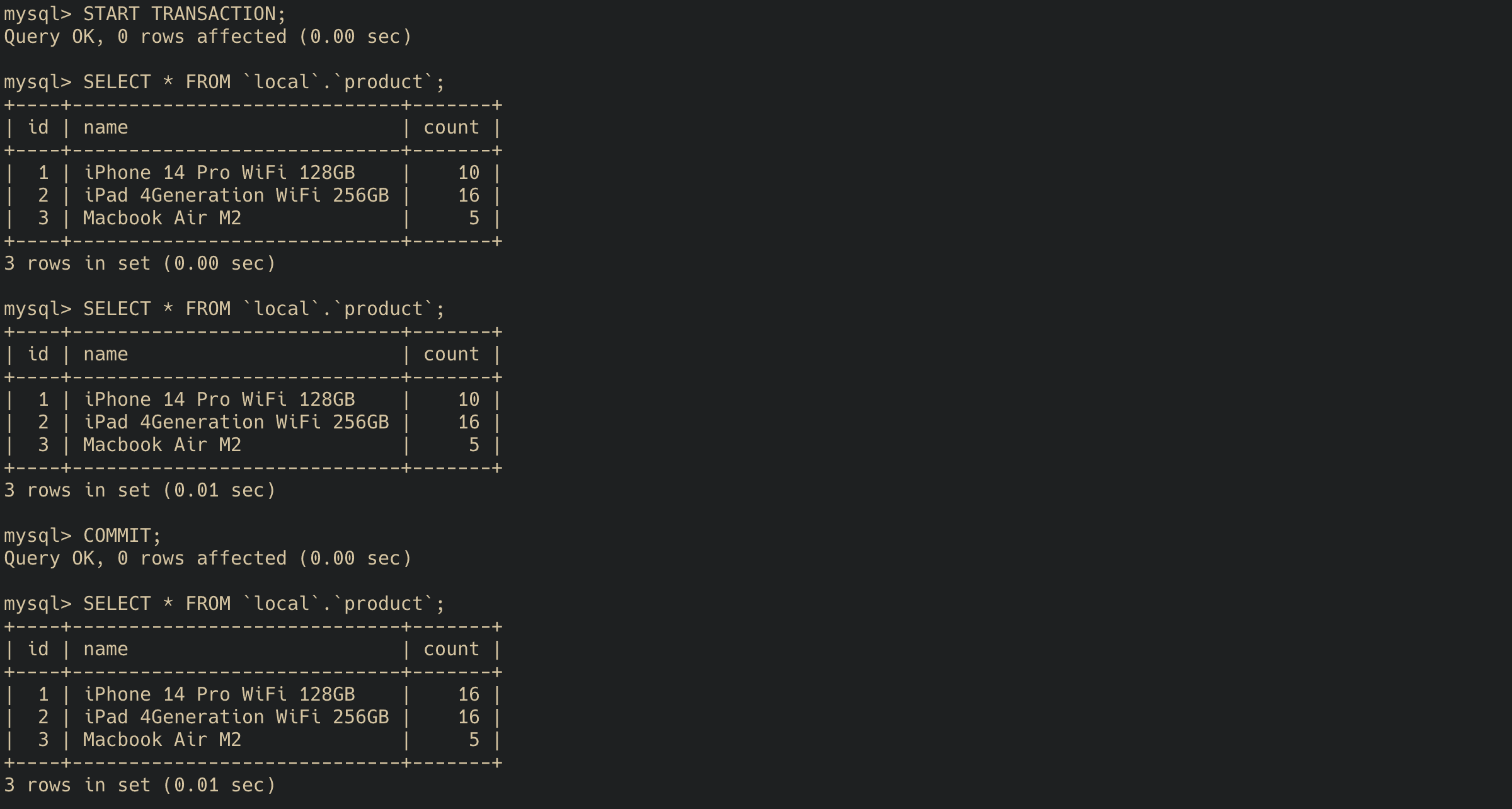
한 트랜잭션에서 아이폰의 수량을 10에서 16으로 변경했다. 그 과정에서 또 다른 트랜잭션에서는 데이터를 조회해봤다. 트랜잭션 안에서 데이터를 두번 조회해도 같은 결과를 얻었다. 두 조회 시점은 다른 트랜잭션에서 아이폰의 수량을 변경한 전/후이다(커밋한 전/후). 마침내 트랜잭션을 끝내고 나서야 앞서 커밋되어 변경된 데이터가 조회된다. 이로써 NON-REPREATABLE READ가 발생하지 않음을 알 수 있다. 그리고 이렇게 데이터에 대한 여러 버전을 관리한다고 해서 이를 MVCC(Multi Version Concurrency Control)라 부른다. MVCC로 인해 모든 문제가 해결되었을까, 아니다. 여전히 다른 문제가 있다. 바로 PHANTOM READ다.
PHANTOM READ는 트랜잭션 안에서 데이터가 조회되지 않았다가 갑자기 데이터가 조회되는 문제 상황을 말한다.
Transaction B:

Transaction A를 먼저 시작한 후, Transaaction B에서 위와 같이 에어팟을 새로 넣고 커밋하자. 이후 Transaction A 안에서 에어팟이 조회될까? 그렇지 않다. Transaction B는 Transaction A보다 이후에 일어났기 때문이다. 그러나 Transaction A에서 UPDATE 쿼리를 날린 이후에는 어떨까?
Transaction A:
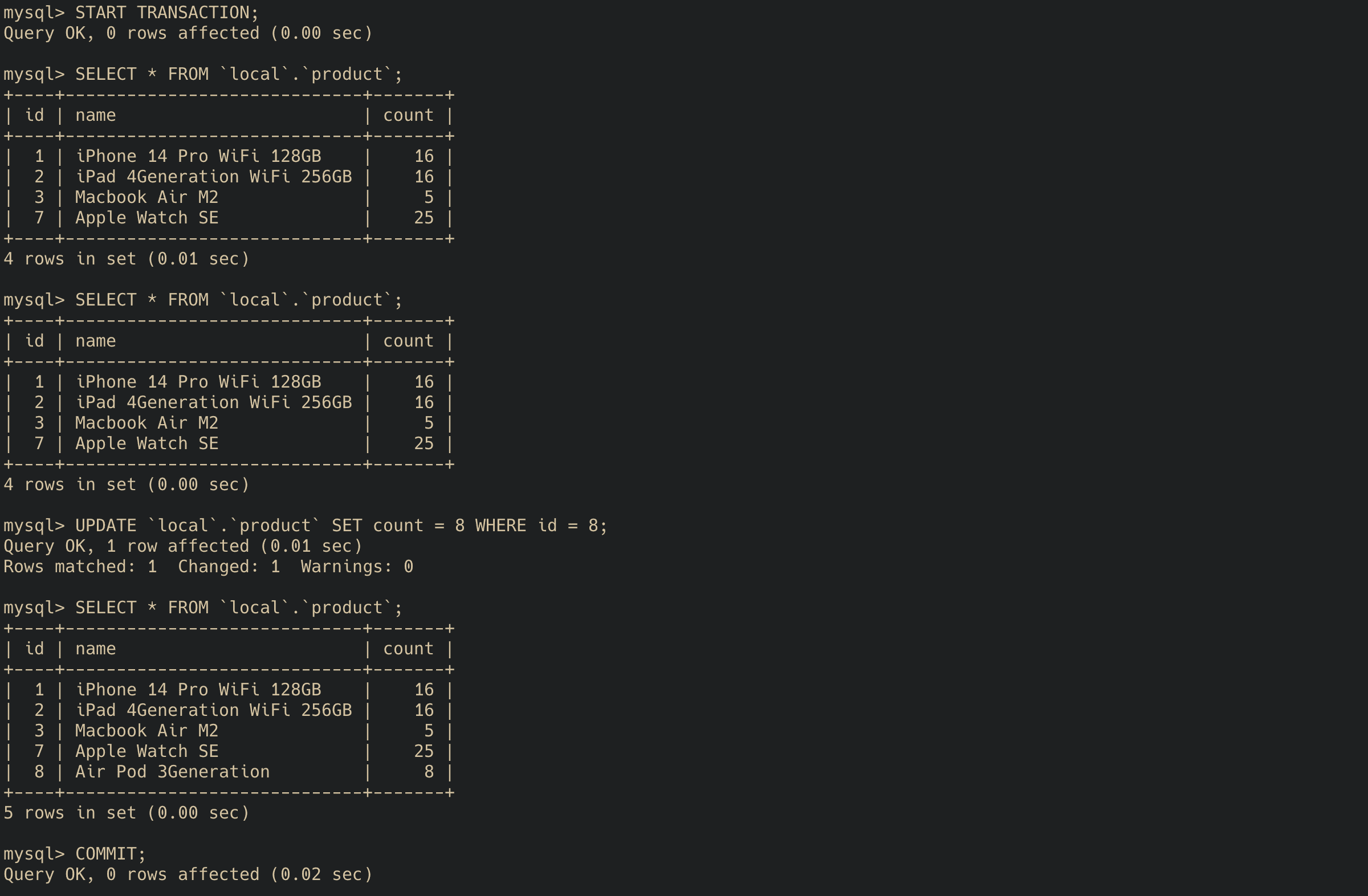
맨 처음 조회했을 때와 Transaction B에서 커밋한 후 조회했을 때의 결과는 같았다. 그러나 UPDATE쿼리를 실행한 이후에 데이터를 조회하면 갑자기 에어팟 데이터가 읽히는 것을 볼 수 있다. 이 상황을 PHANTOM READ라 한다.
SERIALIZABLE
SERIALIZABLE 격리 수준에서는 앞서 말한 모든 문제가 발생하지 않는 격리 수준이다. 격리 수준에서 가장 엄격한 격리 수준으로 다수의 트랜잭션들 사이에서 발생할 수 있는 문제를 피했지만, 그 만큼 처리 속도에서는 성능이 떨어진다. InnoDB 엔진에서 읽기 쿼리는 아무런 잠금을 하지 않지만 이 격리 수준에서는 공유 잠금(Shared Lock)을 해야한다.